c++
C++Book
库
1 | #include <iostream> |
在上面的代码我们应该都知道我什么都没有实现,这只是在简单的阐述一下c++库的重要性,也可以说是让我们更深刻的认识到有些代码的意思是什么。
- #include,using (预编译指令)
- iostream (是c++标准库,方便使用cout,cin,)
- using namespace std (是命名空间,std,因为在库里大多数都有std命名空间的部分,所以规定这些名称为std)
结构函数
- 关键字struct+结构名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#include <iostream>
using namespace std;
struct point{
int a=5;
int b=10;
};
int main(){
point *p=new point; //在堆内存里new了内存
p->a=10;
p->b=5;
cout<<p1->a<<"\t"<<p1-><<endl;
point p1,p2; //在栈内存里实现,还把poit里的参数全部给p2使用
cout<<p1.a<<"\t"<<p1.b<<endl;
cout<<p2.a<<"\t"<<p2.b<<endl;
}
运行结果:1
2
35 10
5 10
5 10
其实结构和类是相似的
联合函数
- 关键字union+名字
1
2
3
4
5
6
7
8
9
10
11
12
13
14#include <iostream>
using namespace std;
union test{
int a;
char b;
};
int main(){
test *p=new test; //在堆内存new了内存
p->a=97;
cout<<p->a<<"的字符表示是:"<<p->b<<endl;
test t1; //在栈内存里实现
t1.a=65;
cout<<t1.a<<"的字符表示是:"<<t.b<<endl;
}
一样的和类相似,在栈和堆内存一样使用,不相同的是:联合函数你可以给变量的其中一个赋值,而另外一个变量会自己把已经赋值的那个变量的值赋给自己。
枚举函数
- 关键字enum+名字
1
2
3
4
5
6
7
8
9
10
11#include <iostream>
using namespace std;
enum Arrow{
eroos,ok,warning,
}
int main(){
Arrow a1=eroos;
Arrow a2=ok;
Arrow a3=warning;
cout<<a1<<a2<<a3<<endl;
}
运行结果:1
2
30
1
2
枚举的特点:它是以字符的形式声明的,但输出的确实整数型的数字
排序
排序的方法有很多,但我们只要理解一种就可以了。我选择冒泡排序1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#include <iostream>
using namespace std;
int main(){
int arr[]={3,10,5,11,6}
for(int i=5-1;i>0;i--){
//把第一个数字设置为最大的数字来跟剩下的数字一起来比较,所以这的次数是总数来减一
for(int j=0;j<i;j++>){
//把每一次大的循环里的数组的大值都往后一个交换位置
if(arr[j]>arr[j+1]){//条件满足就交换位置
int temp;
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
cout<<"排序后"<<endl;
for(int i=0;i<5;i++){
cout<<arr[i]<<endl;
}
}
运行结果1
2
3
4
5
6排序后
3
5
6
10
11
递归函数
递归函数:调用的时候是使用栈内存来实现的,函数一层一层的往下递归,递归的同时会把函数停住,而计算机会重复的把信息保存到栈内存里,遇到递归停止的条件时又会一层一层的往上走在信息停止的那一步,从而实现递归的真正意义。值得注意的是,递归是栈内存的实现,它把信息放在最底层上。每当计算机往上走的时候都是从最低下中读取信息的。栈是先出后入的内存结构。
- 通俗一点的意思就是在本函数里调用自身函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#include <iostream>
using namespace std;
int add(int i){
cout<<"函数开始:i="<<i<<endl;
if(i=5){
return i;
}else
{
add(++i);
}
cout<<"函数结束,返回值为:"<<i<<endl;
return i;
}
int main(){
cout<<add(1)<<endl;
}
函数的结果:`1
2
3
4
5
6
7
8
9
10函数开始:i=1
函数开始:i=2
函数开始:i=3
函数开始:i=4
函数开始:i=5
函数结束,返回值为:5
函数结束,返回值为:4
函数结束,返回值为:3
函数结束,返回值为:2
函数结束,返回值为:1
- 这里的先是返回的自身函数调用的结果,这里编译器里是有五个变量来暂时存储自身函数的值,每当执行到函数返回的时候编译器都会从暂时存储那里把值返回给我们,还有一种理解,就是这个函数里的变量在每次自身函数调用的时候都被隐藏起来了,也就是说每次的自身函数的调用它都有不同的存储位置来让变量重新赋值。其实,递归函数是在返回的时候才是这种函数真真的意义,因为自身函数的最后一次刚好是函数返回值的第一次。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//阶乘的实现
#include <iostream>
using namespace std;
int test(int test1){
int val;
if(test1==1){//递归的停止条件
val=1;
return val;
}else{
val=test1*test(test1-1);
return val;
}
}
int main(){
cout<<"实现阶乘,请输入一个数字:"<<endl;
int t1;
cin>>t1;
cout<<test(t1)<<endl;
}
强调一下,递归的停止条件的重要性,一旦递归没遇到停止的条件就会无穷的死循环,直到计算机的内存都跑完!!!1
2
3
4
5
6
7
8
9
10
11
12#include <iostream>
using namespace std;
int test(int t1,int t2){
if(t2==0){
return 1;//递归的停止条件,t2==0,就返回1
}else{
return test(t1,t2-1)*t1;//上面返回的值来当作第一次的值,然后一直往上计算
}
}
int main(){
cout<<test(3,2)<<endl;
}
运行结果1
9
递归的三大条件
- (有返回值类型,无返回值类型)
- 没有无穷的递归
- 每一种停止的情况都执行(返回)那种情况下的正确操作
- 所有递归函数的调用都能正确的执行操作,那么最后的结果一定是正确的
函数与指针
- 指向函数的指针
1
2
3
4
5
6
7
8
9
10
11
12
13
14#include <iostream>
using namespace std;
int add(int a){
return a;
}
int test(int a){
return a;
}
int main(){
int (*p)(int a)=&add;//指向函数的指针
cout<<P(5)<<endl;
int (*ip[])(int a)={&add,&test};//指向多个函数的指针数组
cout<<ip[0](1)<<ip[1](2)<<endl;
}
函数的结果:1
2
35
1
2
- 这里的指针都是储存在栈内存里的。
预处理
- 格式化代码,去除多余的空格和注释
- 进行一些宏替换
- 包含另外一段代码
- 通过一些条件的判断,动态决定是否编译某段代码
- 宏定义
在定义宏的时候记得不要在定义的后面加分号!!!
1 | #include <iostream> |
运行结果为:1
29
81
- 带参数的宏定义
1
2
3
4
5
6
7
8
9#include <iostream>
using namespace std;
#define MAX 3 //无参宏定义
#define space(x) ((x)*(x)) //声明一个带参数的宏定义
int main(){
for(int i=1;i<=MAX;i++){
cout<<i<<"的平方是:"<<space(i)<<endl;
}
}
运行结果是:1
2
31的平方是:1
2的平方是:4
3的平方是:9
1 | #include <iostream> |
运行结果是:1
2
3
4200
hello,world
helloworld
10
说明了宏的优点有:避免了强类型的检测
- 宏与常量,函数
宏与常量有点相似,但当他们遇上指针和引用之后又会变成什么呢?1
2
3
4
5
6
7
8
9#include <iostream>
using namespace std;
#define x 10
const int y=5;
int main(){
const int &a=x; //ok
const int *p=&y; //ok
cout<<a<<"\t"<<*p<<endl;
}
运行结果:1
10 5
这里给宏使用了引用,给常量使用了指针。还在定义的前面都加了const类型。
但是在这里还是不希望使用引用和指针的方式来操作宏和常量,把宏看作是简单的文本替换,这也是宏的原本意义。
宏不允许重新定义,也就是说一个相同的宏只能被定义一次,要想修改宏的值,你只能先消除它,使用#undef关键来消除,然后你就可以重新定义了。
在c++中有还有内置的宏
1
2
3
4
5
6
7
8#include <iostream>
using namespace std;
int main(){
cout<<__TIME__<<endl; //输出当前代码运行的时间
cout<<__DATE<<endl; //输出当前代码运行的日期
cout<<__LINE<<endl; //输出当前代码的所在行号
cout<<__FIME__<<endl; //输出当前代码的文件路径
}#if #elif #else #ifdef #ifndef
1
2
3
4
5
6
7
8
9
10
11#include <iostream>
using namespace std;
#define a 10
int main(){
#if a<20
cout<<"欢迎使用测试版"<<endl;
#else
cout<<"欢迎使用正版"<<endl;
#endif
return 0;
}
运行的结果:1
欢迎使用测试版
#if类似与我们在以前代码里的if,#else类似与else,#elif类似elseif
#endif,很重要。如果没有它你的程序是跑不起来的。
在c++中有很多预定义函数,这其中有一中是异常处理函数,关键字(try)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#include <iostream>
using namespace std;
int main(){
__try{
int i;
cout<<"请输入一个数字"<<end;
cin>>i;
if(i<=0){
throw "error"
}
}catch(const char *p){//指定抛出异常的类型
cout<<p<<endl;
}catch(...){
cout<<"在main函数里有异常"<<endl;//任何抛出异常的类型都能接受,这里虽然是可以接受任何类型的异常但在前面已经有指定的抛出类型,所以在这里输出的是指定的抛出类型
}
}
e.what(是用来打印异常抛出的)1
2运行结果
error

- bad_typeid:
- bad_cast
- bad_alloc:在new一个内存时,如果没有足够的空间时会抛出异常来,
- ios_base::failure:上一个的异常抛出打印的类型
- logic_error—out_of_range:这是数组下标越界会抛出(out_of_range)类型的异常来
1 | #include <iostream> |
值得注意的是,#ifdef和#ifndef都要有#endif使用,#endif的意思应该是结束if
预定义字符函数
预定义字符函数就是把字符转换成大,小写的字符,在计算机中,我们虽然是以字符的形式输入到计算机中,但计算机本身的运作却是以数字的形式来使用的。值得注意的是,书上写的需要头文件但我这里是不需要头文件的,可能是版本的问题吧,如果有报错的话就加个头文件(cctype)
- toupper()(把字符转换成大写的)
- tolower()(小写)
- isupper()(如果字符是大写的就为true,否则false)
- islower()(同上)
- isspace()(如果字符是空白字符就为true,否则false),一般这个识别的都跟着cin.get()这个函数,因为它识别空格,你可以在它识别空格的时候输出一些东西,下面有个小列子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29#include <iostream>
using namespace std;
void test(){
char a,b;
cout<<"请输入字符"<<endl;
cin>>b;
a=toupper(b)
cout<<c<<endl;
if(isupper(b)){//条件一开始为false
cout<<"转换成功\t"<<a<<endl;
}else{
cout<<"转换失败"<<endl;
}
}
int main(){
test();
char c;
cout<<"请输入字符"<<endl;
do{
cin.get(c);//逐步输入字符
if(isspace(c)){//判断是否符合条件 空格
cout<<'--';
}else{
cout<<c<<endl;
}
}while(c!='.');
cin.get();//识别空格,是空格就打印下面的那句话
cout<<"空格"<<endl;
}
运行结果1
2
3
4
5
6请输入字符
a
转换成功 A
请输入字符
add test
add--test--.
类
类的特征
- 类同时具有成员变量和成员函数。
- 成员可变成私有和共有
- 正常下类的成员变量是私有的
- 类的私有成员只能在本类的函数里面定义和调用
- 类的成员函数可以像普通的函数一样重载
- 一个类可将另外一个类作为自己的成员变量的类性使用
- 函数的i形参可以是类的类型
- 类可以是函数的返回值类型
类的基本
- 所有的成员变量设为私有的
- 用户程序员通过函数作为成员变量的接口来访问变量和完善的规定如何使用每一个公共成员函数
- 任何辅助函数都设为私有的
- 以前的数据和操作的过程都不是独立的,而c++允许我们将一些数据和操作数据的过程放在同一个地方,并封装成一个独立的个体。
- 万物皆对象,这句话对c++程序员来说并不陌生。这并不代表我们缺少对象,对于我们这种高质男来说从来没担心过搞不到对象,因为我们随时随地都可以new一个对象出来,这不是一般人可以做到的,只有真的走进来了才可以的,虽然这个操作在c++中也不算是什么高难度的操作,但我们又不是学到这里就完事的。类和结构是完全可以交换的,唯一不一样的是结构的默认特性是public,而类的默认特性是private。
- 数据类型:由值的集合以及为那些值定义的一组基本运算构成
- 抽像数据类型(ADT):使用数据类型的程序员访问不了值和运算的细节
- 公有对象:不管是在类里还是在外部都能被访问到。
- 私有对象:只能在本类中访问到。
- 保护对象:只能在本类中访问到,在外部是访问不到的。
运算符重载
- 重载运算符,至少要有一个参数的类型是类
- 重载的函数可以是类的友元函数也可以是成员函数
- 不能新建运算符
- 不能改变获取的形参操作符的意义
- 不能改变操作符的优先级
- 不能重载一下操作符(.(圆点)::(作用域)…)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class Son;//先声明Son类
class Bos{
friend int operator+(Bos bos,Son son);//友元函数,用来访问类的私有成员
friend ostream &operator<<(ostream &os,Bos bos);//友元函数,用来访问类的私有成员
private:
int a=10;
int b=5;
}
class Son{
friend int operator+(Bos bos,Son son);//友元函数,用来访问类的私有成员
friend ostream &operator<<(ostream &os,Bos bos);//友元函数,用来访问类的私有成员
private:
int a=5;
int b=10;
}
int operator+(Bos bos,Son son){//运算符重载加号
int a=bos.a+bos.b;
int b=son.a+son.b;
return a,b;
}
ostream &operator<<(ostream &os,Bos bos){//运算符重载<<号
os<<"a="<<bos.a<<"b="<<bos.b<<endl;//把成员变量连接在cout流中
return os;//返回cout,这样就能在main函数中直接打印
}
int main(){
Bos bos;
Son son
cout<<bos+son<<endl;//这要是没有重载加号,是运行不过的
cout<<bos<<endl;//没有重载<<也是运行不过来的
}
谨慎参考,纯属本人理解。ostream,是因为要用到cout流,因为输出流是属于ostream里面的,&,是因为返回的是一个输出流,所以要加个引用来指引。还有就是,重载函数的参数只能是两个,反正在我电脑是两个,超过了就给老子报错,我太难了。
const mutable
- 众所周知,const是常量类型。而mutable是可变的,就像是普通变量。
vector
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#include <iostream>
#include <vector>
using namespace std;
int main(){
vector <int >a{10,20,3,5,1};
a.insert(a.begin(),8);//在向量最前面插入数字8
sort(a.begin(),a.end());//升序
vector <int >::iterator it;//打印
for(it=a.begin();it!=a.end();it++){
cout<<*it<<" ";
}
reverse(a.begin(),a.end());//逆序
for(it=a.begin();it!=a.end();it++){
cout<<*it<<" ";
}
a.clear();//清除向量
vector <int > b;
a.swap(b);
for(it=b.begin();it!=b.end();it++){
cout<<*it<<" ";
}
1 | 运行结果 |
1 | # include <iostream> |
1 | 运行结果 |
- 静态成员函数和静态成员变量
1 | #include <iostream> |
1 | 运行结果为: |
继承
1 | class Teacher{ |
上面的基类用的是构造函数来给自己赋初始化的,所以在派生类也要写上自己的构造函数才算继承基类。
1 | int main(){ |
运行结果是:1
小明的年龄是:18
这里比较特殊的就是成员变量一般是构造函数给的初始化值,但我们在继承的时候往往会遇到问题,就是在声明子类的构造函数会报错,这时我们只能在子类的构造函数中给父类的成员变量赋值,这样才能算是真正的继承下来。
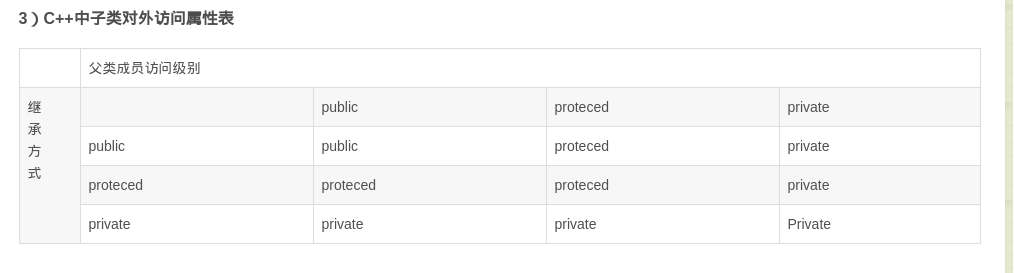
- 继承的方式有三种:public private protected
公有继承, 私有继承, 保护继承
- 公有继承:是以公有的形式来继承的基类,这也就意味着在基类是什么类型的在派生类也是一样的关系。
- 私有继承:是以私有的形式来继承的基类,就是说继承下来的基类都是以私有的形式来继承的。
- 保护继承:是以保护的形式来继承的基类,它是基于公有继承和私有继承的中间,如果你不想在外界被访问到,又想在派生类中被访问,这就可以用保护的形式来继承下来了,但基类的私有成员对象在保护的派生类中依然是私有成员对象。
派生类不会自动的继承基类的构造函数隐藏
- 我们以后难免会在派生类里定义属于它自己的成员变量和成员函数,但当我们在声明和定义的时候有时也会不小心的把成员变量和成员函数与基类的成员变量和成员函数名字相同,这是我们的程序就会出现名字隐藏的现象,对于隐藏就是说当我们的派生类与基类中有名字相同的,就可能会出现隐藏。如果不知道什么时候被隐藏了什么,我们可以加上作用域去看看,在这里,我的建议是,尽量不要在继承类里面用同样的名字,不然你会很自闭的。
- 基类的析构函数最好加上关键字(virtual)写成虚函数,这样在派生类的时候的就能自动调用,而对于,纯虚函数,在派生类中是要重写的性质,因为在基类的纯虚函数是空函数一个,它的本质就是一定要在派生类里面实现它的意义。一个良好的习惯:最好把基类的析构函数写成虚的,这样在派生类中是会自动调用的。
纯虚函数是不能对它进行实例化的,也就是说不能给它创建对象,这是要注意的重点,不能说你定义的是一个纯虚函数,然后你又在main函数里给它创建一个对象来进行一些操作。
在实际开发中,你可以定义一个抽象基类,只完成部分功能,未完成的功能交给派生类去实现(谁派生谁实现)。这部分的功能往往是基类不需要的,或者是在基类中实现不了的,虽然基类完成不了,但强制交给了派生类去实现,否则一样不能被实例化。
抽象基类除了限制了派生类,也实现了多态(也就是说在main函数里,你可以使用基类来调用派生类里面重写的纯虚函数)。
抽象类
- 其实就是在类里面把函数写成是纯虚函数,这样在派生类里就剩下重写这些虚函数。一般把抽象类用来设计一套统一的接口。
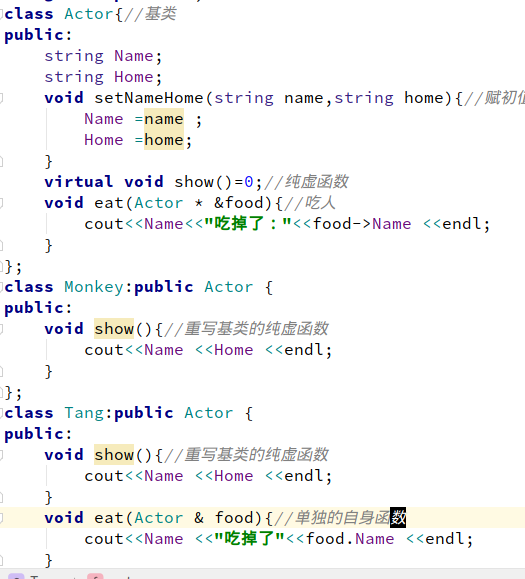
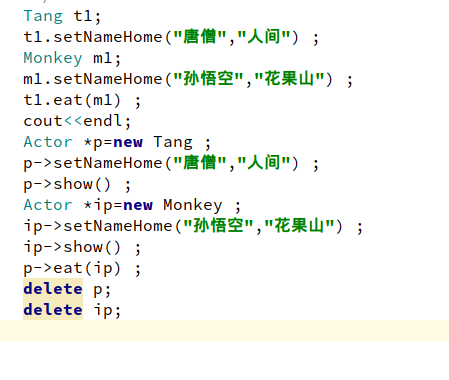
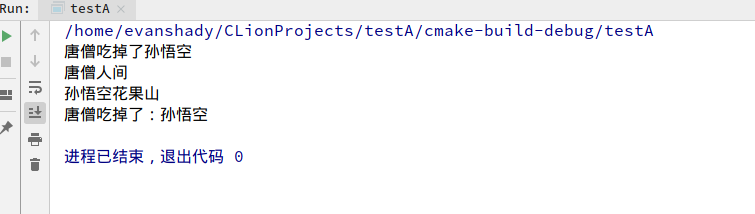
重新认识了类的继承,这里我没有用到构造函数来给成员变量赋值,因为用了构造函数会变的很自闭,发正我是完全不能理解的那种,所以我用来另外一种方法,虽然算不上什么,但我觉得自己理解写出来的东西是可以的。孙悟空吃唐僧,这是多么厉害的,我想这个结果连孙悟空自己也不敢想的,我帮他实现了,嘻嘻。 - 这里的基类是不能被实例化的,因为基类里面的show方法,我用的是纯虚函数来写的,不能被实例化,但在派生类要实现,你不实现的话,你写这个虚函数就没意义了,基类的纯虚函数在派生类你一定要写进去,不要编译器会报错的,
拷贝构造函数
在类中有指针又要多个类的对象的时候最好写一下类的拷贝构造函数
- 在程序中的拷贝是浅拷贝,也就是说在类中只是简单的把普通类型的成员变量复制给另外一个类的对象。但在有引用或者有指针的类里面,如果我们没有声明另外的拷贝构造函数的话,我们的程序就会报错。
- 拷贝构造函数的形参必须是类的类型,该参数必须传引用,而且还要在前面使用const修饰符
- 使用拷贝构造函数在本类中要有指针变量或者多对象
模板
- 关键字 template
1
2
3
4
5
6
7
8
9
10#include <iostream>
using namespace std;
template <typename T>
T add (T a, T b){
return a+b;
}
int main(){
cout<<add(1,2)<<endl;;
cout<<add(10.1,10.2)<<endl;;
}
运行结果:1
23
20.3
1 | #include <iostream> |
运行结果:1
255.55
55.5
拷贝构造函数
test.h
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Test{
string _name;
int _*age;
Test(string name,int age){
_name=name;
_age=new int (age);
cout<<"有参构造函数"<<endl;
}
void(){
cout<<_name<<"的年龄"<<_age<<endl;
}
//深拷贝构造函数
Test(const Test &t){//把类作为函数的参数
_name=t._name;
_age=new int (*t._age);//这里用的是指针来new,因为在本类中它就是以指针的方式来存放的,所以你也只能以指针的形式来启用它。
cout<<"拷贝构造函数"<<endl;
}
~Test(){
delete age;
cout<<"析构函数"<<endl;
}
}main
1
2
3
4
5
6
7
8
9
10#include <iostream>
using space std;
int main(){
Test t1("小明",10);
t1.show();
//类的使用在这以上是没有问题的,这就是浅拷贝额构造函数
//当我们要在有指针(*)或者引用(&)的类中使用二次构造函数,那么我们就要写一个深的拷贝构造函数
Test t2(t1);//这个类的复制是要有深的拷贝构造函数来配合的。因为它符合条件
t2.show();
}程序运行结果
1
2
3
4
5
6有参构造函数
小明的年龄10
拷贝构造函数
小明的年龄10
析构函数
析构函数
其实,拷不拷贝我们要认得类的成员变量有没有指针和引用,一般来说计算机会帮我们直接赋值的,深的拷贝构造函数的问题就是当我们第一次使用构造函数的时候,计算机会跟着自动调用析构函数,把我们之前定义的指针变量给销了,这也得不到我们程序想要的结果啊,不但没有走到我们想要的答案,反倒会给我们的程序报错,这就是个致命的问题,这是我们就只能去解救这个问题,所以我们要用到深的拷贝构造函数。其实在上面的的程序只是简单的想把t1的值赋给t2来间接的让t2有值。
类模板
1 | template <class T>//因为要使用模板,所以在定义模板 |
1 |
|
注意事项
